
Live streams. On-demand videos. Nonstop content. The truth is, it’s a digital-first world, and multimedia content is exploding by the hour. Enterprises are generating massive volumes of data every second. But data alone doesn’t drive decisions — insight does.
For our client, a global leader in SaaS technology specializing in end-to-end cloud-managed live and on-demand video infrastructure, the opportunity was clear: transform this content into insight.
.jpg)
The challenge? Building intuitive, AI-driven solutions that could derive actionable insights through natural language interactions and make sense of rich multimedia content at scale.
To address these needs, we identified two primary use cases and implemented them using Databricks:
- Conversational Analytics Agent using Databricks Genie
- Speech-to-Text Transcription Pipeline with Whisper Models
Our team designed and implemented both to enhance data intelligence capabilities while maintaining strict security and performance standards.
Conversational Analytics Agent Using Databricks Genie
Databricks Genie is an advanced conversational AI feature integrated into the Databricks Lakehouse ecosystem. It enables users to query data in natural language, transforming complex data analysis into an intuitive process. Genie is particularly beneficial for non-technical users, analysts, and engineers, as it democratizes access to insights without requiring deep technical expertise.
- Conversational Queries: Users can ask questions like "What are the top-performing videos this month?" and receive actionable insights instantly.
- Integration with Unity Catalog: Ensures secure and governed access to datasets.
- Real-Time Insights: Delivers responses quickly, enabling faster decision-making.
.jpg)
Architecture and Implementation Overview
The Conversational Agent was designed to enable business stakeholders to interact with analytics data through natural language queries. Our architecture consisted of several interconnected components that worked together to deliver an intuitive, conversational interface for data exploration.
Our solution began with robust data preparation, where raw datasets were cleaned, transformed, and modeled into optimized gold-layer views, which were then connected to the Databricks Genie space. The Genie Conversation API serves as the backbone for integrating Genie capabilities into the custom application, enabling stateful conversations that allow users to ask follow-up questions and naturally explore data over time.
Training and Fine-tuning Process
Rather than traditional model fine-tuning through weight adjustments, we employed a contextual training approach. This involved providing Genie with comprehensive context about available tables, their relationships, and sample queries. The training process included:
.jpg)
This approach essentially "teaches" Genie how to interpret user questions in the context of the client's specific data structure and business domain. The continuous feedback loop allows for progressive improvements, with each iteration refining Genie's ability to accurately interpret and respond to user queries.
Query Capabilities and Intelligence Features
The Conversational Agent supports a diverse range of analytical inquiries, including:
- Basic analytical questions: Retrieving viewership metrics, audience demographics, and content performance statistics
- Follow-up questions: Maintaining context from previous questions to provide coherent conversation flow
- Comparative analysis: Processing questions like "most viewed vs. least viewed content" or "views in USA compared to views in Canada"
- Forecasting: Predicting metrics such as expected view counts for future periods or special events
- Inference questions: Analyzing causality, such as explaining viewership drops or predicting outcomes of content strategy changes
- Investigative analysis: Examining relationships between metrics, like whether increased ad frequency correlates with user drop-offs
- Mention-based queries: Processing requests about specific content titles or series without requiring exact matching
- Keyword interpretation: Understanding business-specific terminology and value ranges (e.g., defining "popular" or "extreme" viewership)
Security and Compliance Measures
Data security was implemented through multiple layers:
- Data masking: Sensitive information is obscured using Databricks' built-in MASK function, which replaces sensitive data with masked values while preserving analytical value
- Column-level security: Restricting access to sensitive columns based on user permissions
- Unified Catalog integration: Leveraging Databricks' governance features to maintain compliance with data privacy regulations
- Response filtering: Implementing guardrails to prevent the LLM from revealing sensitive information
Deployment Architecture
The solution was deployed as a custom application using Databricks' app hosting capabilities with Streamlit integration.
.png) This approach provides several advantages:
This approach provides several advantages:
- Seamless integration: The application connects directly to the Genie Conversation API
- Unified environment: Both the backend intelligence and frontend interface exist within the Databricks ecosystem
- Simplified maintenance: Updates to data or models automatically reflect in the application
- Enhanced security: Leveraging Databricks' security framework rather than exposing data to external systems
The deployment architecture follows a pattern like the Streamlit demonstration with Databricks SQL shown in search result but extended to incorporate the Genie Conversation API for natural language processing.
Speech-to-Text Transcription Pipeline
Developed by OpenAI, the Whisper Automatic Speech Recognition (ASR) model represents a new benchmark in audio transcription. Designed to handle real-world audio, including background noise, multiple accents, and rapid speech, it delivers near-human transcription accuracy even in noisy environments. Variants such as WhisperX and Faster Whisper further optimize performance for specific use cases.
.jpg)
Model Evaluation and Selection
The second use case involved developing a high-performance speech-to-text transcription pipeline for analyzing audio content. We evaluated multiple Whisper model variants:
- OpenAI Whisper: The base model providing good accuracy but with optimization opportunities
- WhisperX: An enhanced version with improved speed
- Faster Whisper: Optimized implementation selected for production due to superior performance
The evaluation included comprehensive testing across model sizes (tiny, small, medium, large), examining the trade-offs between transcription accuracy and computational efficiency. After extensive benchmarking, Faster Whisper emerged as the optimal solution, balancing accuracy and latency requirements.
Implementation Architecture
.png)
The speech-to-text pipeline was implemented in two distinct modes to address different use cases:
.jpg)
Performance Benchmarking:
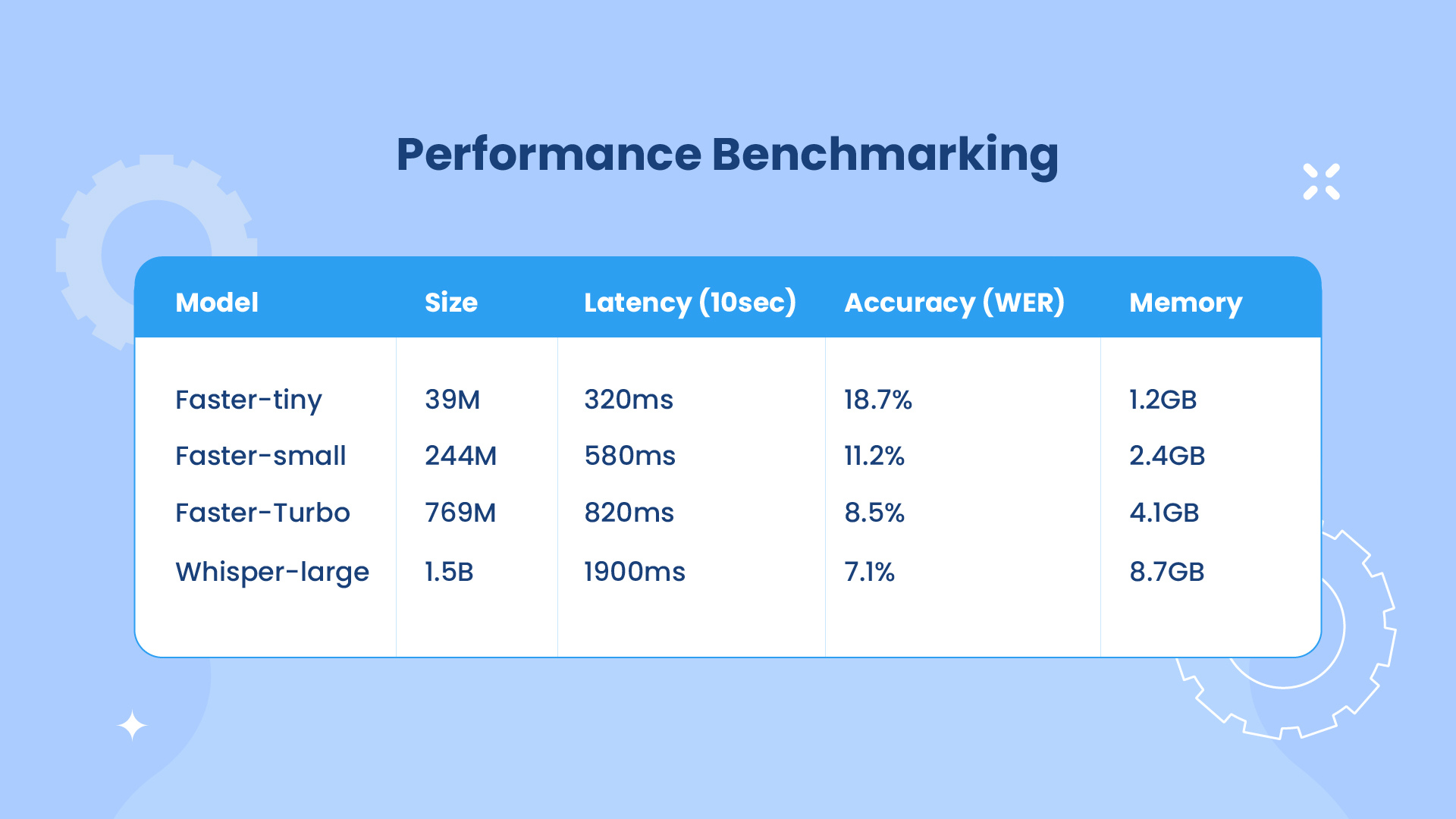
Selected Faster Whisper Turbo as optimal balance (8.5% WER at <800ms latency). WER (Word Error Rate) measures the percentage of errors in a transcribed output compared to the correct reference. A lower WER indicates higher transcription accuracy.
Technical Optimizations and Parameters
Several technical optimizations were implemented to enhance performance:
- Beam search optimization: Fine-tuned beam search parameters for optimal accuracy/speed tradeoff
- Model quantization: Reduced model precision to improve inference speed without significant accuracy loss
- Batch size tuning: Identified optimal batch sizes for both streaming and batch processing
- Audio preprocessing pipeline: Implemented noise reduction and audio normalization to improve transcription accuracy
- Diarization integration: Added speaker identification capabilities to distinguish between different speakers
Integration with Analytics Pipeline
The transcription results flowed directly into a comprehensive analytics pipeline:
- Results were written to Delta tables with appropriate schema design
- Sentiment analysis was performed on the transcribed text
- Performance analytics extracted insights about content quality and audience engagement
- Results were made available for the Conversational Agent to query through natural language
Performance Metrics and Benefits
The solution delivered impressive performance metrics.
.jpg)
.jpg)
From Content to Clarity
With both solutions live, the client has unlocked a faster, smarter way to work with data: whether it's structured analytics or hours of raw audio. The Conversational Analytics Agent empowers teams to ask business questions in plain English and get answers in seconds. The Speech-to-Text Pipeline turns voice into valuable insights, opening up an entirely new stream of data-driven decisions.
Here’s what changed:
- Faster decisions: Time-to-insight dropped from days to moments
- Wider access: Business users now explore data without writing a single query
- Sharper content strategy: Analytics combine structured and unstructured inputs for a fuller picture
- Lean operations: Less reliance on data teams for routine requests
- Lower costs: No need for third-party transcription services — and no compromise on security
Next steps? Expanding Genie’s reach across more datasets, enhancing speaker detection, and pushing the limits of conversational analytics to support even more advanced use cases.


